
最近、GANについて興味をもち色々調べていましたが、最初に提案された2014年の論文について解説しているものが少なかったので、簡単にまとめてみました。
素人のブログですので、間違い等ございましたらご連絡していただければ幸いです。
Generative Adversarial Nets のできること
最初に提案されたGANは、入力した画像と似た画像を生成することができます。
どんな画像を生成することができるのかと言うと、「mnist」「Toronto Face Database」「CIFAR10」での画像生成をおこなっています。
「mnist」は、機械学習でよく用いられる手書き数字の画像になります。
「TFD(Tronto Face Database)」は、トロント大学が持つデータセットで、グレースケールの顔画像になります。入手方法は、色々探しましたが、手に入れる方法は直接問い合わせるぐらいしか見つかりませんでした。
「CIFAR10」は、機械学習でよく用いられる10種類のカテゴリがあるカラー画像になります。
GANが提案されるまで
GANが提案される前の画像生成モデルでは、ボルツマンマシンなど最尤推定の明示的な確率密度を計算する際の確率計算の近似が難しく、またImageNetなどの大規模なデータセットでうまく生成できないことが問題となっていました。
GANの構成
それでは、GANの構成について、他のサイトで詳しく解説してあるものが多くあるので、ここでは学習法については簡単に解説していきます。
GANは2つのネットワークを交互に学習させることで画像を生成できるようになります。
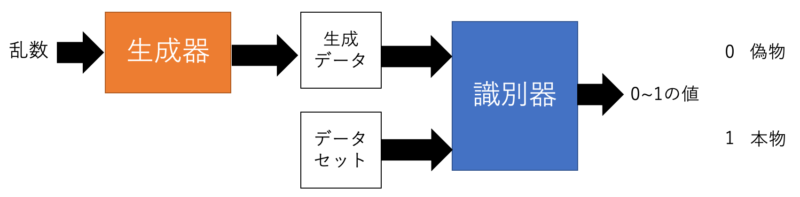
「生成器」と「識別器」があります。
「生成器」は、乱数を入力することで、出力として画像を生成します。
「識別器」は、画像を入力することで、出力として0~1の値を出力し、0.5未満の場合は偽物、0.5以上の値は本物と識別します。
生成器の学習
生成器は、生成器の誤差関数を小さくなるように更新していきます。
L=[1-生成画像の識別結果]
識別器の学習
逆に識別器は、識別器の誤差関数を大きくなるように更新していきます。
L=[データセットの識別結果]+[1-生成画像の識別結果]
まとめ
今回は、一番最初に提案された「Generative Adversarial Nets」について、簡単に解説していきました。
次に学ぶべきGANは、「Conditional GAN」や、「DCGAN」あたりでしょうか。
参考書としては以下がおすすめです。翻訳された本ですので、少し読みにくいものとなっていますが、詳しく解説してあるので読む価値はあります。
また、実際にpythonで書いたGANについても今後投稿予定ですので、そちらも完成次第見ていただければと思います。

